
In ERP environments, disaster recovery often gets reduced to “database replication.” In real life, recovery succeeds only when data consistency, integration flows, batch schedules, identity services, and network routing are all considered together. Even if the application comes back up, the outage is not really over for the business if the integration queue is corrupted, user sessions have dropped, or the routing for external systems has not been updated.
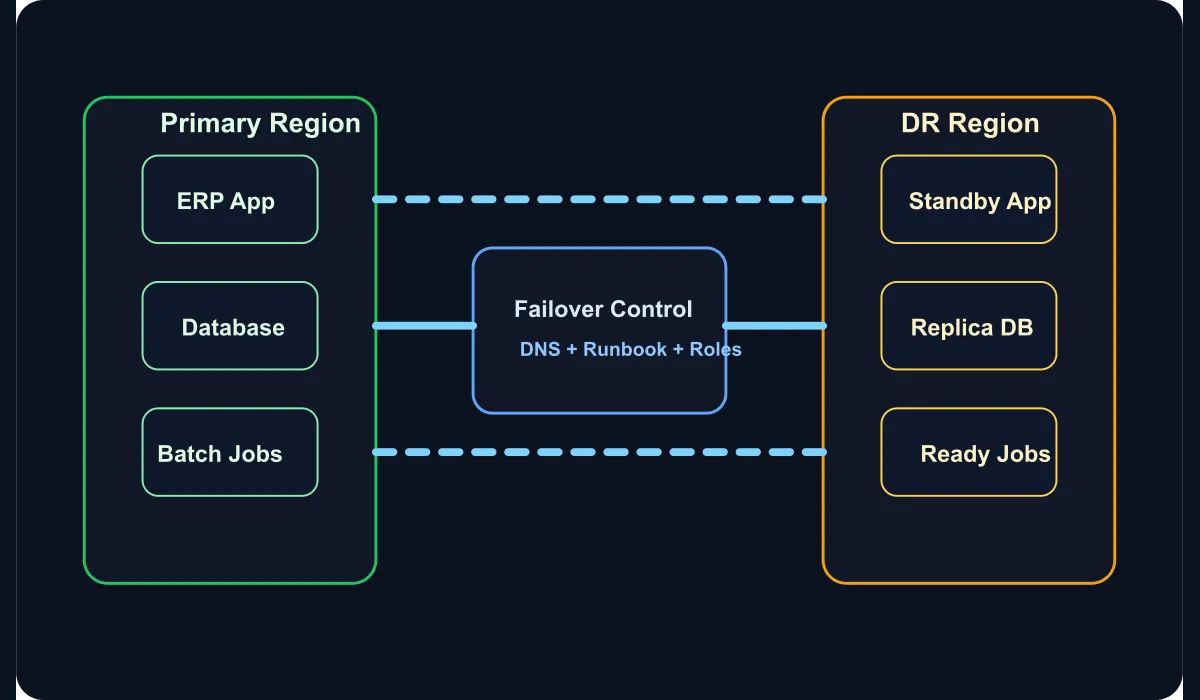
Why is the active-passive model still common?
For enterprise ERP workloads, active-active is not always the right call economically or operationally. Because of license costs, data consistency requirements, and the need for sequential processing of critical flows, active-passive often ends up being the more controllable choice. But that choice only holds if the passive site is genuinely kept ready.
If the passive side is left at a “the servers exist” level, what’s being managed isn’t disaster recovery — it’s optimism.
Which components belong at the center of the plan?
The most critical layers in an ERP system are usually:
- Application servers and session management
- Database and transactional consistency
- Message queue or integration broker
- External system connections
- Batch and scheduled workflows
Skip even one of these and failover may look feasible on paper, but in practice the business units cannot return to production.
What should you watch for around data consistency?
In an active-passive setup, the first question shouldn’t be “how many minutes until we’re up again?” It should be “which data point are we returning to?” In some ERP processes, even a few minutes of lost data triggers a financial or operational reconciliation.
So the following points need to be defined clearly:
- The target RPO and RTO values
- Which tables or modules need near-synchronous protection
- The replay strategy for integration messages
- How data conflicts will be prevented during failback
Why does the network and publishing layer deserve its own heading?
A lot of organizations design data replication carefully but think about how to redirect users and integration partners to the new region only at the last minute. A solid design has these layers ready ahead of time:
- DNS failover or a controlled routing policy
- Internal ACLs and firewall rules mirrored across both regions
- VPN, MPLS, or leased line terminations validated on the passive side
- Where required, third-party access allowlists prepared in advance
If, in the middle of an incident, the network team and the application team are running their own separate discovery, the lost minutes pile up fast.
How should operational roles be defined?
In active-passive scenarios, command clarity matters as much as technical correctness. The structure I usually recommend looks like this:
- Incident commander: owns decision flow and communications.
- Infrastructure owner: drives region activation, network, and compute steps.
- Application owner: validates ERP service health and the batch impact.
- Integration owner: tests external system flows.
If these roles aren’t clear up front, technical teams end up double-checking the same thing while critical steps go unowned.
Is a plan valid without a drill?
No. Especially in environments like ERP where downtime is expensive, you cannot trust the document without a realistic drill. A good drill includes:
- A synthetic business scenario for specific modules
- User login, critical transaction flow, and reporting tested together
- At least one end-to-end flow validated through an external integration
- A post-drill improvement list closed with a date and an owner
Conclusion
Active-passive disaster recovery for ERP infrastructure is not just about renting a second site. The real value emerges when data, publishing, and operations are stitched into a single recovery story. For teams chasing reliability in enterprise architecture, the right question is not “do we have a DR environment?” but “in a real outage, can we bring the business processes back in an orderly way?”