
A lot of organizations still treat DNS as a plain name resolution service. In real production environments, the DNS layer directly drives where traffic terminates, which region takes over in a disaster scenario, and how fast clients recover. When teams talk about load balancers, reverse proxies, and service mesh but leave DNS design in the background, they’re usually neglecting the very first decision layer of the architecture.
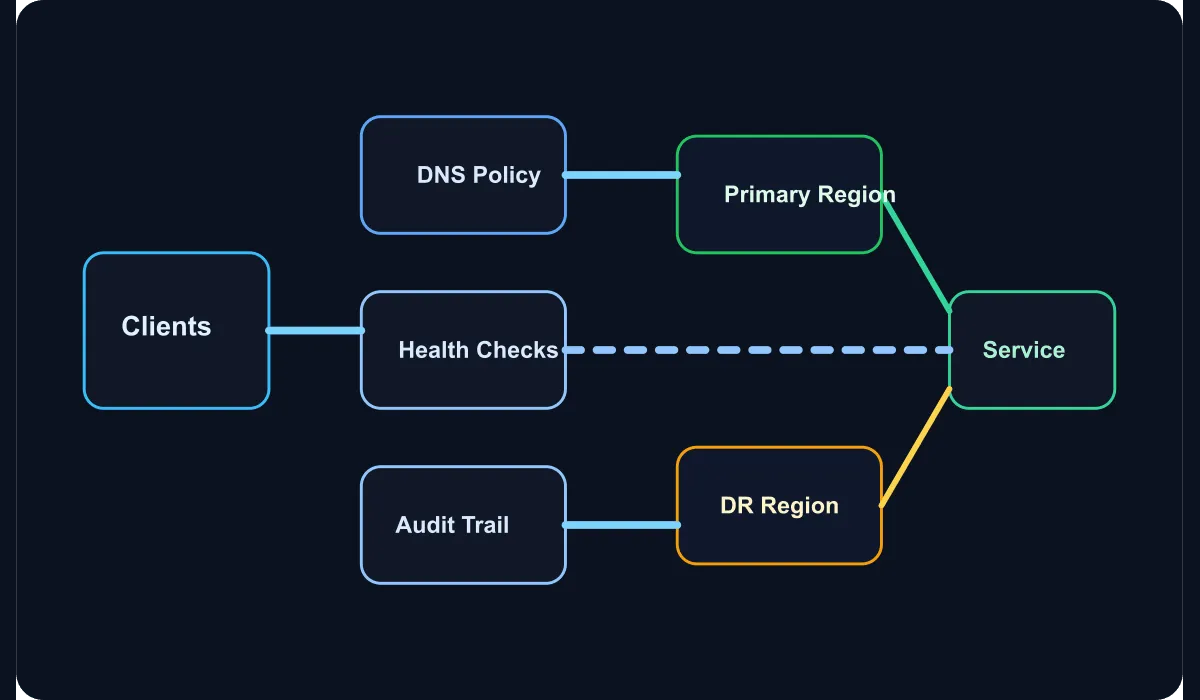
Why is DNS an architectural decision layer?
In enterprise networks, the user or application almost always reaches the system first through a domain name. That’s why the answers to the following questions get decided at the DNS layer:
- Which data center or region should the traffic go to?
- Which service endpoints should take priority?
- How long should each record stay cached?
- During an outage, how quickly can clients pivot to the new target?
Each of these maps directly to availability, performance, and operational control.
The most common bad design
In setups where records are defined manually and TTL values are picked at random, the DNS layer slowly turns into invisible technical debt. Especially in ERP, integration services, and enterprise API publishing, these mistakes get expensive:
- Publishing the same service under different naming schemes across environments
- Designing failover logic only at the load balancer level
- Decoupling health checks from the lifecycle of DNS records
- Falling back to old endpoints during a disaster because TTLs were too long
The setup looks quiet while it works, but during an incident it stretches recovery time for no good reason.
How do you build a solid routing model?
At enterprise scale, a practical model usually has four pieces:
- Consistent naming: service, environment, region, and access type all defined under the same pattern.
- Health signal: whether endpoints actually respond is monitored centrally.
- Policy layer: priority, weight, geo, or failover rules are explicit.
- Low-friction change flow: DNS changes stop being manual operations sitting on a ticket.
Without this model, DNS becomes a registry where every team uses its own method.
Where does DNS get more critical?
DNS design should be treated as a first-class architectural component especially in environments like:
- Setups with multiple data centers or cloud regions
- Topologies where ERP and enterprise integration services pass through different access layers
- Network segments where internal and external clients need different routing policies
- Services where traffic must be moved in a controlled way during planned maintenance
In these situations, DNS becomes a change management tool, not just a service availability mechanism.
How should health checks tie into DNS?
The classic mistake here is monitoring health check data in a separate system and never wiring it back into the DNS layer. If records are unaware of health, routing decisions stay static. A good design ensures:
- The health signal is meaningful at the application level, not just the port
- “TCP is open” is not treated as enough proof of life
- The operations team can observe regional priority changes
- Every record change leaves an audit trail
That way DNS decisions are fed by data and remain operationally observable.
Do internal services need split-horizon DNS?
In enterprise networks, the same service often has to resolve to different targets for internal and external clients. Split-horizon DNS is useful here, but applied loosely it makes debugging painful. So:
- Ownership of internal and external records should be clearly defined
- Documentation should track the different resolutions for the same service name
- Observability should make it possible to see which client is receiving which resolution
Otherwise, “works for me, doesn’t work for you” issues become structural.
Conclusion
DNS-based service routing in enterprise networks is an invisible but critical control plane. Designed properly, it does much more than resolve names — it simplifies maintenance windows, accelerates recovery during disaster scenarios, and centralizes service publishing policy. For teams that want to make the very first decision in their network architecture more deliberately, this is exactly where to start.