
For a long time, enterprise data center networks were carried by core-distribution-access tiers. The model looks manageable up to a certain scale; but as east-west traffic, virtualization density, and micro-segmentation needs grow, the hierarchical structure often turns into a bottleneck. When traffic patterns shift while the network backbone stays the same, latency, blast radius, and operational complexity grow together.
Why is L3 Clos coming up now?
In traditional designs, network growth is typically met with bigger core devices, more complex STP behavior, or an ever-growing list of policy exceptions. The limits of that approach show up as:
- Unnecessary tier traversal even for traffic outside the same rack
- Failure propagation driven by large L2 domains
- Capacity planning that gets harder as scale increases
- A wide impact area during maintenance windows
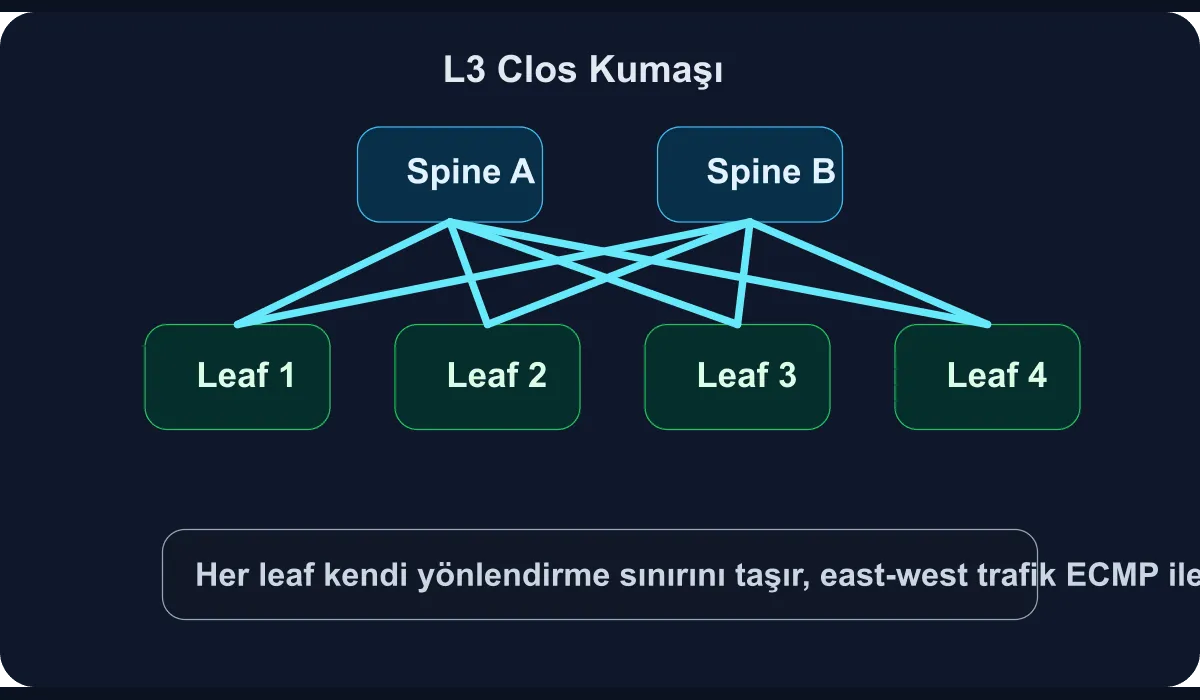
The L3 Clos fabric, by contrast, aims to scale capacity horizontally with many small and predictable links. That’s why the spine-leaf model has become a sensible choice not only for hyperscale providers but also for enterprise data centers.
What truths must be clarified before migration?
Many teams start by drafting a hardware list and only then arrive at the architectural decision. The healthy order is the reverse. The following questions need answers first:
- What is the dominant traffic pattern?
- Which workloads are sensitive to low latency?
- Where do the L2 dependencies actually end?
- Can the IP plan and routing boundaries be redesigned?
A Clos built without that analysis will only carry the old habits forward on new gear.
What is the biggest enterprise advantage of L3 Clos?
The most important advantage I see is how it simplifies both failure handling and scaling. Losing a leaf or spine is no longer a dramatic event, because capacity is spread across many similar links. Policy boundaries are also drawn more clearly:
- Routing at the rack or pod level
- Cleaner integration with EVPN-style control planes
- Decoupling segmentation from L2 dependencies
The most common migration mistake
Enterprise teams often carry old VLAN habits over to the new fabric unchanged. The topology looks different, but the operating model doesn’t change. For the migration to actually deliver value, these areas must be revisited:
- Prefix plan
- Route summarization boundaries
- Server and hypervisor uplink model
- Out-of-band management separation
- Telemetry and capacity observability
Without transforming these areas, a Clos becomes nothing more than a more expensive cabling project.
How should the operations team prepare?
A new topology demands new troubleshooting muscle. Teams need shared practice on:
- How is ECMP behavior verified?
- What is the expected impact when a leaf is lost?
- In what order is a BGP neighbor problem investigated?
- How are cable and optic faults isolated quickly?
In enterprise transformations, an operational training program belongs in the plan as much as the technical architecture itself.
Conclusion
Migrating to an L3 Clos fabric in enterprise networks is not just a decision about scaling the data center. It is also a redefinition of the network’s failure domain, maintenance cadence, and capacity logic. Real value emerges when an organization treats this migration not as an equipment refresh project, but as a transformation of its routing and operating model.