
In enterprise systems, a large share of network outages does not start with bad routing; it starts with seemingly small name-resolution issues. A wrong TTL, inconsistent resolver behavior, regional latency, or service-discovery records that fail to update in time—any of these can ripple through the entire application layer. Particularly in environments where hybrid cloud, on-prem data centers, and legacy ERP services share the same ecosystem, DNS is not just an infrastructure detail; it is a critical architectural component.
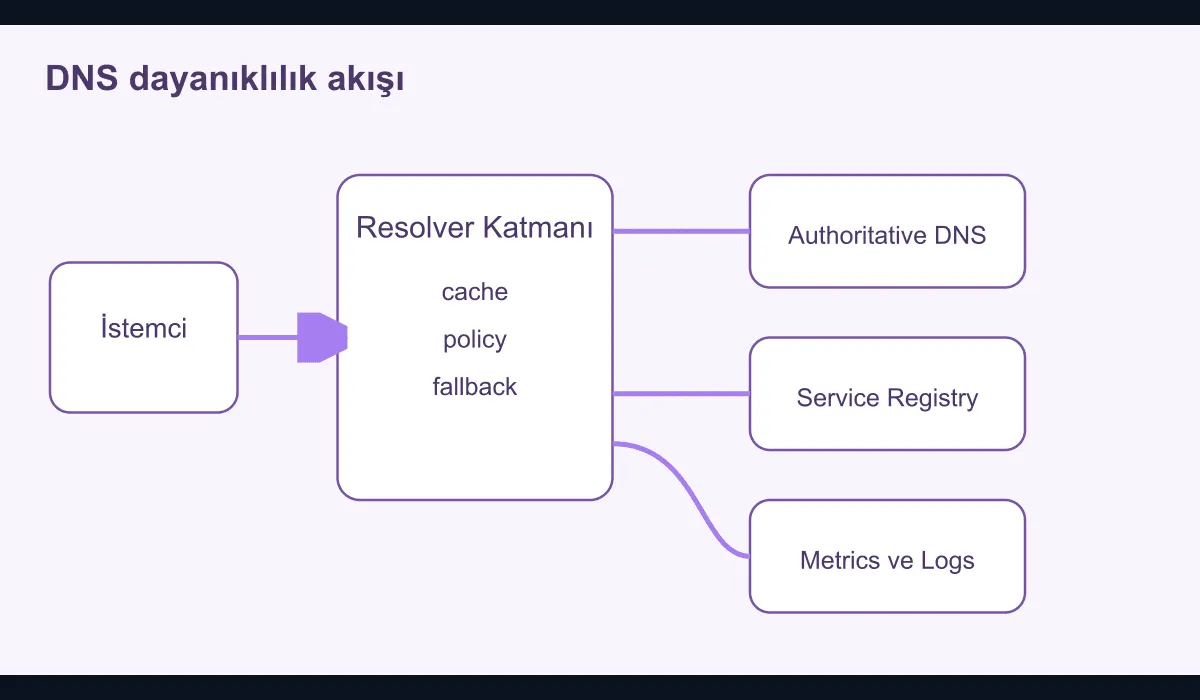
Why is the problem so often underestimated?
Because DNS is usually treated as a foundational service that “just works.” But the root cause of many application-side symptoms is hiding in this layer:
- New nodes appearing late
- Traffic continuing to hit old IPs
- Internal services failing to reach each other during a regional outage
- Inconsistent answers across different resolver chains
These problems get worse as microservice sprawl, multi-environment deployments, and hybrid connectivity grow.
Which principles underpin a resilient model?
For the design of enterprise DNS and service discovery, the principles that matter are:
- Separating the authoritative zone management from the resolver layer
- Drawing a clean line between internal and external namespaces
- Choosing TTL values that match operational needs
- Tying record lifecycle to health status
- Producing observability data from the DNS layer itself
The goal here isn’t only to add more responding resolvers; it is to design name resolution to behave reliably.
Where does it get harder in hybrid infrastructure?
DNS behavior in hybrid setups is not the same as in a single-environment world, because:
- On-prem and cloud resolver chains can be different.
- Split-horizon records can produce inconsistent results.
- VPN or private-link latency can affect resolution time.
- Legacy systems may not adapt well to short TTL changes.
So when you design a service-discovery model, looking only at the Kubernetes or cloud-native side is not enough.
What needs to be measured?
For a healthy DNS layer, the “is the service up” metric on its own does not cut it. These should also be tracked:
- Resolution latency
- NXDOMAIN and SERVFAIL rates
- Error distribution per resolver
- Propagation time after a record change
- The most-queried critical service records
Without these signals, the root cause of an incident is usually found late.
Conclusion
Enterprise DNS and service discovery is one of the least visible but most critical resilience layers in your infrastructure. A correct design rests on resolver continuity, healthy record lifecycles, and strong telemetry. In well-running systems, DNS is invisible; in poorly designed ones, it is the thing you notice the most.