
One of the most exhausting parts of server security is having to reapply controls you know perfectly well on every new server. SSH settings, disabling unused services, auditd, time sync, journald limits, and basic firewall policies are well known in most organizations; yet knowing something and having it as an enforceable standard are not the same. Building a hardening baseline with Ansible moves security from a one-off checklist into a sustainable operational practice.
Why does a baseline matter?
In many teams security hardening lives under the heading of “we’ll look at it after install.” Two problems follow:
- Drift accumulates between newer servers.
- It is hard to track which control was actually applied.
The baseline approach defines the minimum acceptable security standard in code. So even when servers change, the standard stays the same.
Which controls should you start with?
Rather than starting with an extremely long initial list, choose changes that are both impactful and safe. The controls I tend to add first across most Linux estates are:
- Disabling password login for SSH
- Restricting root login
- Removing unnecessary network services
- A baseline inbound policy via UFW or nftables
- Verifying
auditd,chrony, and log rotation
These can be expanded based on the organization’s requirements; but in the first step they deliver fast wins.
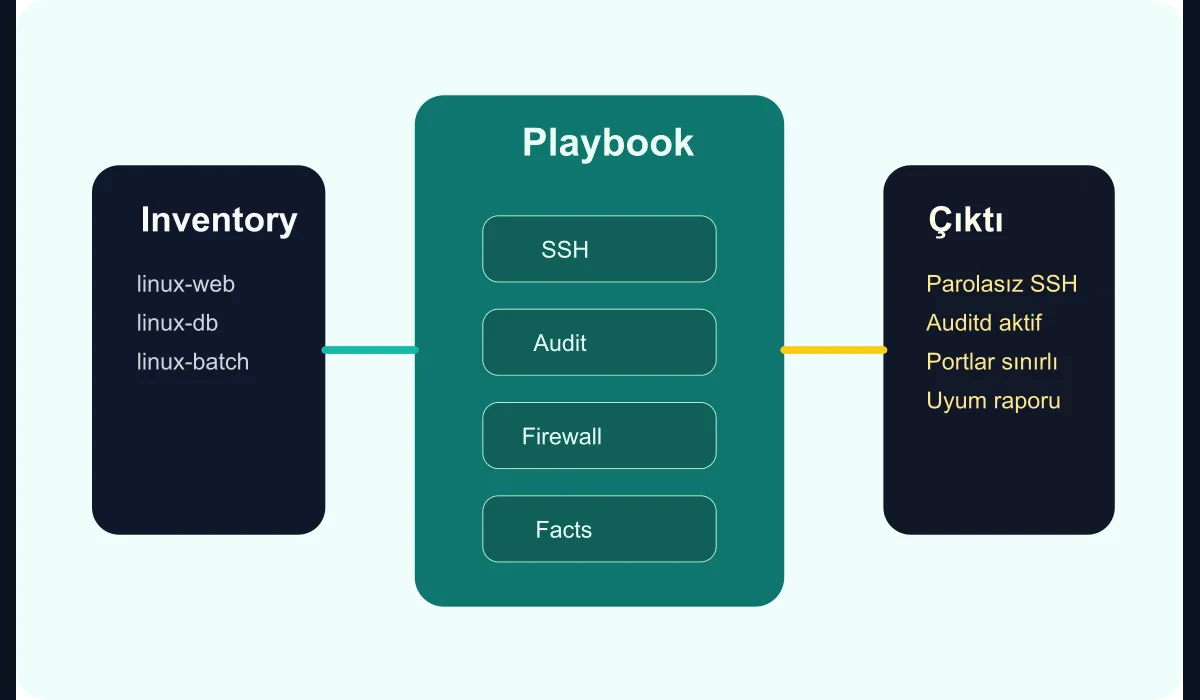
How should the role structure look?
A single huge playbook looks easy in the short term; in the long run it becomes hard to maintain. Splitting the baseline into small, understandable roles is healthier:
common-packagesssh-hardeningaudit-and-loggingfirewallcompliance-facts
This structure makes it easier to figure out which layer caused a regression and to expand the baseline in a controlled way.
- name: Harden baseline
hosts: linux_servers
become: true
roles:
- common-packages
- ssh-hardening
- audit-and-logging
- firewallWhy is idempotent design critical?
When you manage security with Ansible, one of the most important principles is that the playbook reliably produces the same result every time it runs. If a task makes unnecessary changes on the second run, two problems emerge: trust drops and the operations team avoids running the automation regularly.
For this reason, tasks should as much as possible:
- Define file contents explicitly
- Use controlled service restart conditions
- Manage exceptions per environment via variables
- Produce a verification output for each control
How do you build compliance visibility?
The weakest link of server hardening is being forgotten after it is applied. To prevent that, every run should produce at least a minimal compliance output. For example:
- Which hosts passed?
- Which hosts have detected drift?
- Which controls were skipped due to exceptions?
- When was the last run?
When these data are correlated with CI/CD, AWX, or a central log system, the baseline turns into a living control mechanism.
Things to watch for in production
For critical settings such as SSH hardening, gradual rollout matters. Instead of applying changes to all hosts in the group at once:
- Run on a pilot host group.
- Add automatic verification commands.
- Make a post-change access test mandatory.
- If successful, roll out to remaining groups.
This flow improves security while reducing the risk of losing access.
Conclusion
Building a server hardening baseline with Ansible aligns security expectations with operational reality. Once you define a standard minimum, security stops being a checklist remembered only on audit day. As servers multiply, the value comes not from individual interventions but from a reliable and repeatable baseline.