
Applying network policy in Kubernetes environments is the right approach almost everyone agrees on; yet many teams keep postponing it because they fear breaking production. The cluster ends up growing, services multiply, and east-west traffic becomes an invisible free-for-all. Cilium makes this transition more manageable because it joins observability and policy enforcement on the same plane. Following the right order makes step-by-step tightening possible instead of “shutting everything down overnight.”
Why is a gradual approach essential?
Jumping directly to a deny model without a clear understanding of which pod talks to which service generates production incidents, especially with legacy services. So the first goal is not to “block” but to make existing behavior visible.
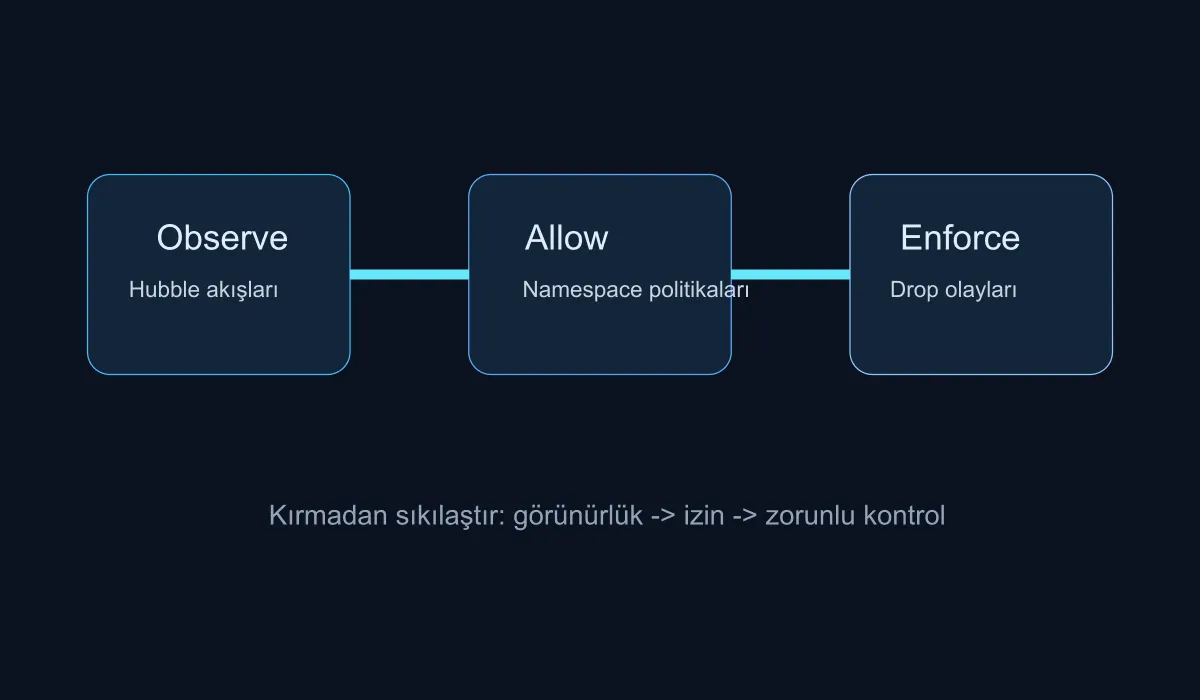
A healthy transition is thought of in three phases:
- Observing the traffic and dependencies
- Defining the allow model per namespace or application
- Gradually moving into enforced policy mode
This sequence reduces unnecessary friction between security and operations.
How do you build the starting inventory?
First, you need to understand which services actually need to talk to each other. At this stage:
- Separate ingress and egress directions
- Note shared services like DNS, metrics, tracing, and secret management
- Treat batch jobs and cron workloads separately
- Prevent ad-hoc debug pods from acting without policy
Cilium Hubble or equivalent visibility tooling delivers value precisely at this point. The goal is not just to count connections but also to understand application ownership.
Which principles help when writing policies?
It is right to start the first rule set in the smallest blast radius. For example, begin around a single namespace or a single application. While writing policy, this approach helps:
- Create a separate policy group for shared platform services.
- Define intra-application traffic and cross-namespace traffic separately.
- Explicitly allow DNS and observability dependencies.
- Maintain a team standard for
matchLabelsusage.
apiVersion: cilium.io/v2
kind: CiliumNetworkPolicy
metadata:
name: payments-api-egress
spec:
endpointSelector:
matchLabels:
app: payments-api
egress:
- toEndpoints:
- matchLabels:
app: postgresHow do you stage enforcement?
In practice, this flow gives a safe outcome:
- Collect visibility only on selected namespaces.
- Build the recommended policy set.
- Enable the rule on low-risk services.
- Watch event and drop logs.
- Move into production-critical namespaces in a controlled way.
In this model the rollback path is clear and change windows become more manageable.
Operational watch points
- If application labels are messy, the policy is unsustainable.
- If namespace boundaries were designed badly, policy count explodes.
- Policy violations should be watched not only by security but by the platform team too.
- Network policies that are not connected to a GitOps pipeline turn into a manual exception store quickly.
In short, the topic is not just writing YAML; it is disciplining the cluster contract.
Conclusion
Tightening network policy with Cilium is a strong step that moves Kubernetes security from theory into practice. The key to success is not an aggressive start but following a gradual path from visibility into enforcement. When you model service dependencies correctly, you raise the security level while keeping production risk manageable.