
In ERP systems, schema changes are too often treated as merely a database task. In reality, however, what changes is not just the table — it is the integrations running concurrently, the batch flows, the reporting queries, and the operations team’s ability to debug. For this reason, a healthy ERP modernization effort does not aim to say “the migration ran”; it aims to build a schema migration pipeline that can be safely rolled back when necessary.
Why are schema changes more delicate on the ERP side?
Because ERP data is usually not the contract of a single application but a shared agreement among dozens of business workflows. Renaming a field or adding a mandatory column can simultaneously affect these layers:
- Application servers
- ETL and reporting flows
- Integration services
- Batch processors
- Authorization and audit logs
In modern microservices, this blast radius can sometimes stay within service boundaries; in the ERP world, however, change usually touches more systems horizontally. That is why a reversible design is a fundamental requirement.
What is a reversible schema migration pipeline?
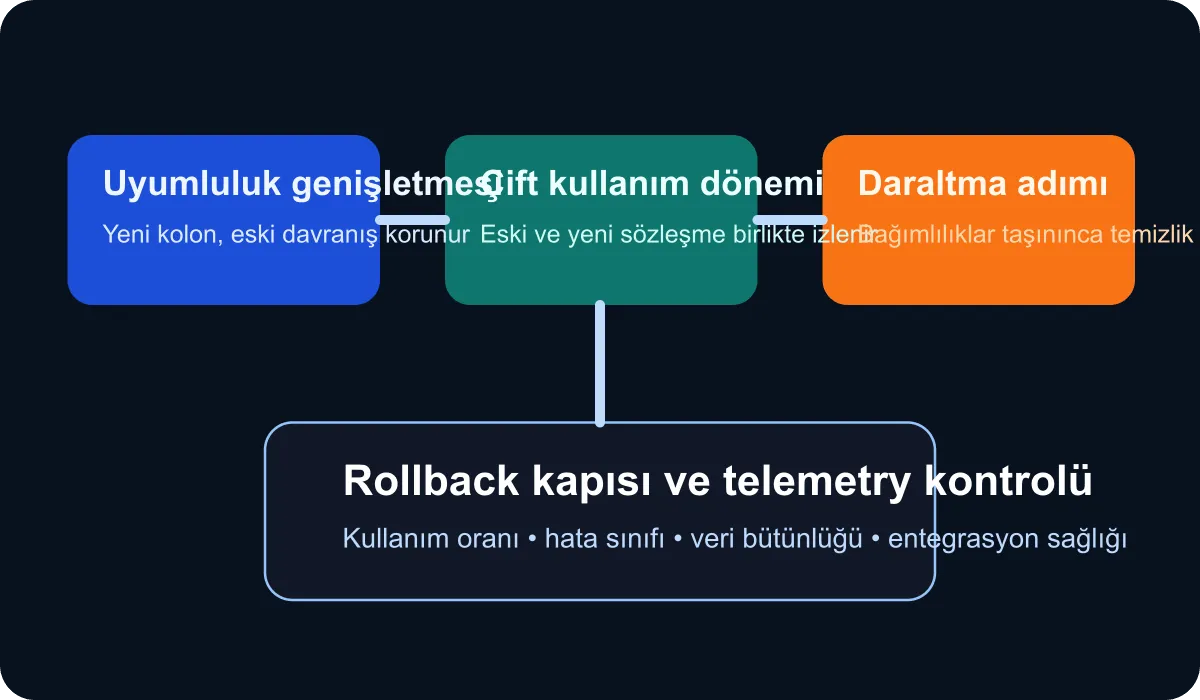
I find it useful to think of this model in four phases:
- Compatibility expansion: Add the new schema fields, but do not break existing behavior.
- Dual-read or dual-write period: The application uses the old and new structures together in a controlled fashion.
- Traffic and data observation: Use telemetry to confirm which dependencies still consume the old field.
- Contraction and cleanup: Remove the old field only after it has truly been confirmed abandoned.
The fundamental advantage of this approach is that it does not turn the change into an irreversible move in a single step.
Where is the real mistake made?
Most teams think the work is over once the migration file runs successfully. In practice, breakage usually surfaces two days later — in a nightly batch, in a reporting query, or in an external integration. The reason is that the schema change has been technically applied but its behavioral impact has not been measured.
For this reason, the following control gates should be written into the pipeline:
- Which queries are still using the old field?
- Which integration version cannot consume the new schema?
- Which batch job is producing data inconsistencies?
- If a rollback happens, will it cause data loss or only behavioral change?
Do not underestimate the compatibility layer
In ERP infrastructures, the compatibility layer is sometimes treated lightly because it is “temporary”; in fact, it is the most valuable protective surface. For example, if a new document_status_v2 field is being added, the application can read both the old and the new field for a period of time. When necessary, a write-time conversion adapter can keep the two structures in parallel.
Thanks to this layer:
- Application teams can transition between different versions in a controlled way.
- The reporting team can adapt their queries safely, with a delay.
- Reverting to the old behavior in case of an unexpected error does not break data integrity.
The critical point here is not to leave this period open-ended and to define exit criteria from the start.
This pipeline cannot be managed without telemetry
If the schema migration pipeline is not observable, teams will make decisions by intuition. In transformations like this, I consider it necessary to track at least the following signals:
- Old vs. new field usage ratio
- Error classes after the migration
- Failure rate in reporting and integration queries
- Latency in data mapping or transformation
On the ERP side in particular, the question “did it break?” is less valuable than “who is still depending on the old behavior?” That answer only emerges when the application and data layers are observed together.
A decision window, not a change window
Enterprise teams often plan a nightly release window; what is really needed, however, is a decision window. In other words, it should be clear in advance which signal will allow the release to continue, which signal will halt it, and under what condition a rollback will be triggered. In this model, the change is not a test of bravery; it is controlled option management.
In my view, a well-defined decision window includes:
- A responsible technical owner
- A business-impact representative
- A data integrity checklist
- A rollback boundary and a data-rollback method
Conclusion
A reversible schema migration pipeline in ERP infrastructures handles database change together with an operational trust model. Migrations performed without a compatibility layer, telemetry, and clear rollback gates may look successful at first, but at enterprise scale they produce expensive surprises. The robust approach is to expand the change in small steps, measure behavior, and contract only when dependencies have truly migrated.