
During outages, the communication model determines recovery time just as much as the technical fix. Plenty of teams are technically strong; yet because status updates, decision ownership and stakeholder language are not crisp, incidents stretch out, trust erodes, and bottlenecks form on both the operations and the communication side at the same time. A technical leader’s job is not just to put the right person on the right task, but to design information flow as an architectural discipline.
Why do you need a communication architecture?
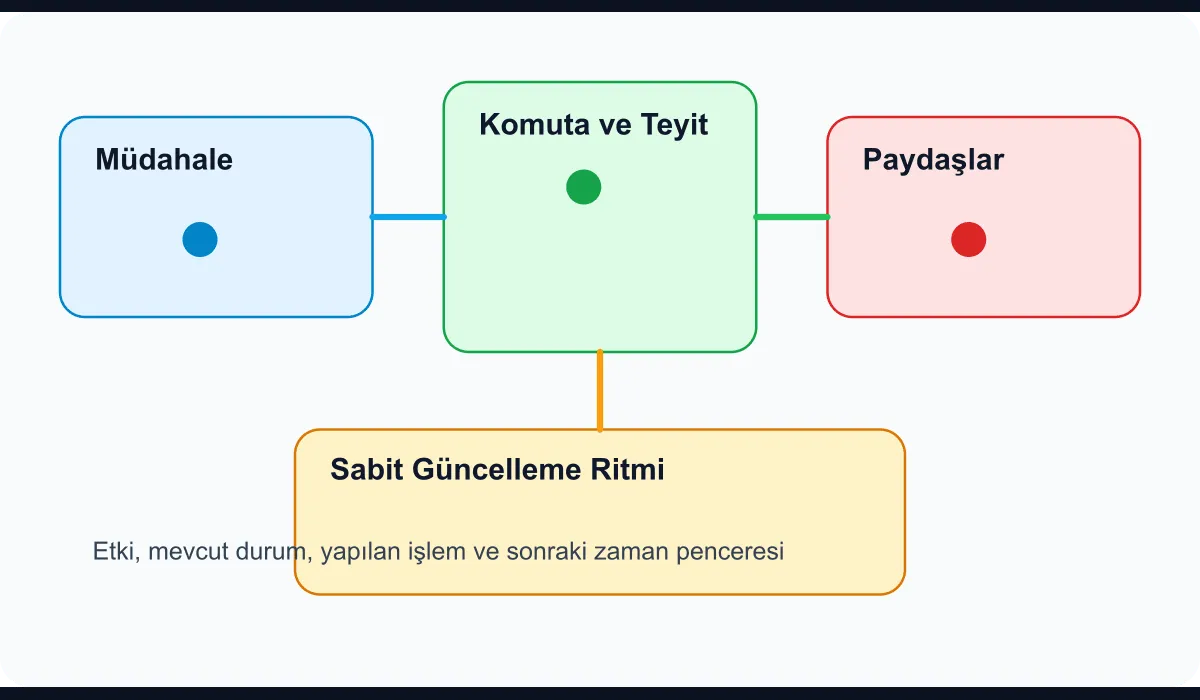
In enterprise environments a single incident produces four different expectations at once:
- The operations team wants to reduce the symptom.
- The application team is trying to understand the root cause.
- Management wants to hear about impact and time to recovery.
- Support or customer-facing teams need clean sentences for external communication.
When all of these expectations are managed in a single channel, everyone talks over each other. The moment the need for technical detail and the need for an executive summary share the same thread, neither the responders can work calmly nor does the business side feel reassured. A communication architecture exists to resolve this collision.
A three-channel model is the most pragmatic approach
The model I have found most effective consists of three separate streams:
- Response channel: Commands, hypotheses and technical confirmations live here.
- Status channel: Short, verified updates are shared on a five- or fifteen-minute cadence.
- Stakeholder channel: Impact is conveyed to management, product and customers in plain language.
The benefit of this model is straightforward: the first channel is optimised for speed, the second for accuracy, and the third for trust. Rather than trying to feed everyone with the same text, you produce three views of the same truth.
Define roles by function, not by name
During an incident, instead of asking “who’s on this channel?”, you should be clarifying “which role is on whom?”. In comparable situations, these roles tend to simplify the work meaningfully:
- Incident commander: Drives priority order and decision rhythm.
- Technical driver: Coordinates diagnosis and intervention steps.
- Communications lead: Prepares and publishes external stakeholder updates.
- Scribe: Records the timeline, decisions and action items.
In smaller teams one person may carry two roles; but if at all possible, separate the incident commander from the communications lead. Because as the technical decision rhythm picks up, producing calm, controlled communication demands separate attention.
The skeleton of a status update
A good status update should not be elaborate, it should be repeatable. The template I recommend is built around four points:
- Impact: Who or which system is affected?
- Current state: Is the outage ongoing, is there partial recovery?
- Action in progress: Which fix path is the team currently on?
- Next update time: When will the next confirmed information be shared?
This structure proactively answers the questions management asks most often. If there is uncertainty, write it down honestly. Manufactured confidence is more expensive than honest uncertainty.
Which sentences erode trust?
In technical leadership, communication quality almost always shows up in the language. The following patterns are risky:
- “The issue seems to be resolved.”
- “Probably network-related.”
- “We’ll get back to the team.”
- “There’s an issue but the scope isn’t clear.”
These phrases come across as both indecisive and ownerless. Instead, more controlled phrasing is required:
- “Impact has narrowed, monitoring continues.”
- “Root cause is not yet confirmed; we are working on two hypotheses.”
- “The next confirmed update will be shared at 14:30.”
The goal here is not exaggerated certainty, it is controlled honesty.
The technical leader’s real contribution is translation
Senior engineers most often focus on getting the technical solution right; but in an enterprise setting, what creates outsized impact is the ability to translate that technical correctness into different stakeholder languages. When describing a database latency event, you need to be able to tell the product team “the order flow is queued”, and tell management “transaction volume is affected but no data loss is confirmed”. Telling the same event in different sentences while staying anchored in the same reality is a leadership practice.
Conclusion
Incident communication architecture is one of the invisible load-bearing columns of operations culture. Clear role distribution, a steady update rhythm and disciplined language let the technical team work more calmly; meanwhile stakeholders feel more trust with less speculation. For a technical leader, the maturity signal is not just resolving the incident, but holding the organisation’s information order together throughout it.