
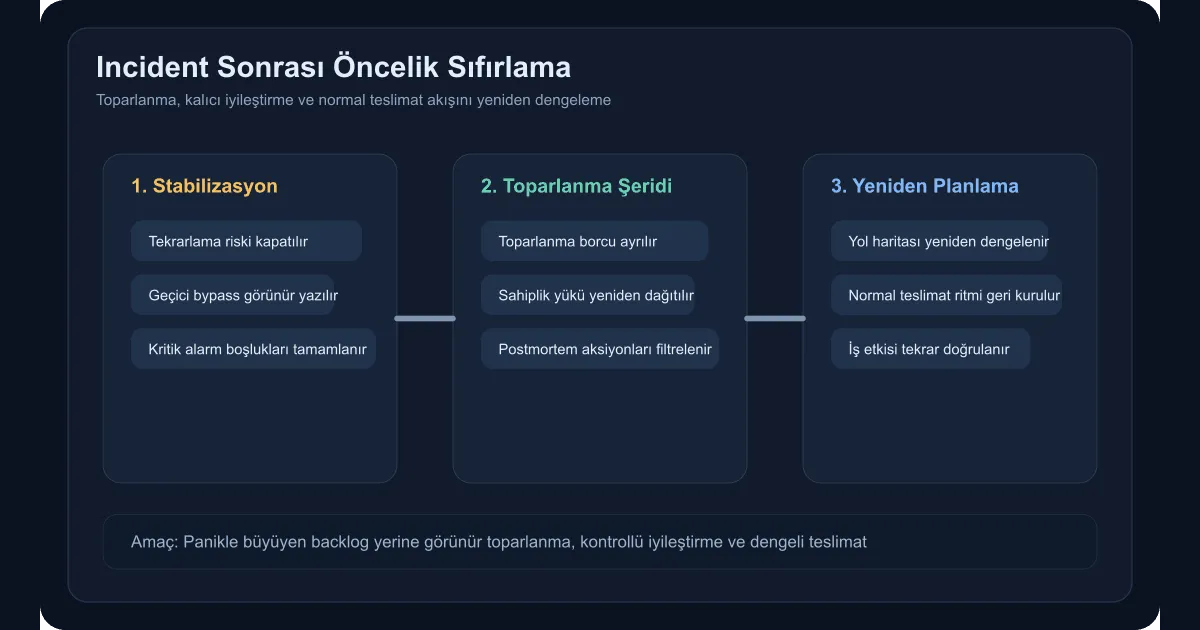
When an incident closes, the calendar quiets down, but the system hasn’t really calmed yet. The moment the alarms go silent, most teams swing one of two ways. Either they try to restore every paused piece of work at once, or they push the debt that surfaced during the outage into a vague “we’ll look at it later” pile. For a tech lead, the real test starts right there. The first few days after an incident aren’t just a recovery window — they’re the priority-reset moment that shapes the next two weeks, sometimes a whole quarter, of the team’s output.
Why even reset?
During an outage, things naturally bend out of shape:
- Planned deliveries stop
- Operational load lands on a few people
- Workarounds start to look permanent
- New risks become visible
If the team doesn’t deliberately reframe that picture, the backlog swells, decision quality drops, and the “the incident is over but we still haven’t actually recovered” feeling becomes a permanent state. Priority-reset discipline is exactly what prevents this. It puts systematic rebalancing ahead of emotional reaction.
First move: don’t keep everything in one list
Plenty of teams produce a single task list after the incident. But mixing production-safety items with roadmap items in the same bag creates fuzzy decisions. The first split I prefer to draw is:
- Operational gaps that need to be closed immediately
- Learning items and durable improvements
- Normal deliveries that can resume
Without this separation, “prioritization” tends to turn into a fight, because everyone is defending work at very different risk levels in the same list.
Which items count as truly urgent?
After an incident, not every finding is critical. The tech lead’s job here is to produce a threshold, not panic. Items that usually belong in the first wave look like:
- Open configuration mistakes that would replay the same symptom
- Insufficient alarms or visibility gaps
- Missing pieces that erode rollback or change confidence
- Response steps that depend on a single person
By contrast, larger architectural shifts shouldn’t be smuggled into the “let’s do it now” bucket using the incident as a justification. The team’s focus capacity is already lower in the post-incident period. The big work might be right, but it’s not necessarily the first work.
How do you rebalance the roadmap?
The tech lead’s role here isn’t to “stop everything”. The actual job is showing which deliveries can safely keep moving. Three questions I find genuinely useful:
- Does this work increase the root cause or recurrence risk of the incident?
- Has the focus this work needs already been consumed by the operational load these last few days?
- If we delay this delivery, is the business impact bigger than the operational improvement we’d skip?
Looked at through that lens, some roadmap items keep going as-is, some get scoped down, and some get deliberately deferred. The critical part is that these calls aren’t made “because that’s how it feels” — they’re made through a visible frame.
You need a separate vocabulary for recovery debt
I’ve found “recovery debt” is a useful phrase to name what happens after an incident. It’s a different beast from classic technical debt. Recovery debt is things like:
- Temporary bypasses or manual workflow steps
- Access opened during the incident that was never closed
- Observations and timeline notes that never got persisted
- Maintenance work pushed back because of fatigue
If this debt stays invisible, the team’s calendar looks normal but the system is running wounded. So the tech lead has to put these items in a visible recovery lane, not in the “we’ll get to it later” pile.
Why is team psychology part of this?
Because teams don’t return to baseline at the same speed after an incident. Some engineers shift back into their normal rhythm right away. Others spend a few days more cautious and a bit scattered. Senior leadership here doesn’t mean cranking up productivity pressure — it means simplifying the decision surface.
A healthier approach usually looks like:
- Don’t open a flood of new parallel work in the first week
- Redistribute critical ownership
- Leave breathing room for the people who carried the response
- Filter postmortem actions by impact, not by count
If you set this up, the incident stops being a sprint-eating trauma and becomes a measured recovery program.
Which metrics actually help?
Looking only at “is the root cause closed?” leaves you short. The signals I find more meaningful:
- Whether the same symptom triggered another alarm
- How long the temporary work opened during the incident takes to close
- How clearly the deferred deliveries get rescheduled
- How many days operational load takes to return to normal
- The redistribution of work among people who carried the response
These metrics show whether the team has actually recovered. The moment the incident ends and the moment its impact ends are usually not the same moment.
The most common tech-lead mistake
The mistake I see most often is treating postmortem actions as the new backlog reality. Every incident throws off dozens of ideas, and they don’t all carry the same weight. The tech lead’s job isn’t to produce ideas. It’s to filter out which ones actually change system behaviour.
The opposite mistake is just as bad: closing the incident with a single ticket. In that case the team feels faster in the short term, but a few weeks later the same fragility comes back wearing different clothes.
Wrap-up
For tech leads, post-incident priority reset isn’t about reshuffling meetings on the calendar. It’s the ability to read operational gaps, recovery debt, and normal delivery rhythm in the same picture. Done well, the team moves with more clarity after an incident, not with more speed. That’s where real maturity shows: not in fixing the issue, but in not losing your sense of direction afterwards.