
In ERP modernization, one of the most neglected yet most expensive problems is test data. Without data that resembles production, integration, reporting, and process scenarios cannot be validated realistically. Copying real production data, however, creates unacceptable risk in terms of security, compliance, and access management. The way to resolve this dilemma is not one-off data obfuscation scripts but building a repeatable test data masking factory.
Why is a factory approach necessary?
In many organizations, test data preparation usually goes like this: a copy is taken from production, a few critical columns are masked manually, the file is shipped, and teams move on saying “this will do for now.” This model can survive a small dry run, but it is not sustainable in the ERP world. Because data is not just a customer name or phone number. Order relationships, financial flows, supply chain references, HR records, and cross-module keys move together.
If masking only changes a handful of fields, two problems emerge:
- Sensitive data can be re-identified through unexpected relationships.
- Test scenarios lose their meaning because business rules are broken.
That is why you need a production line that preserves data behavior, not a “masked dump.”
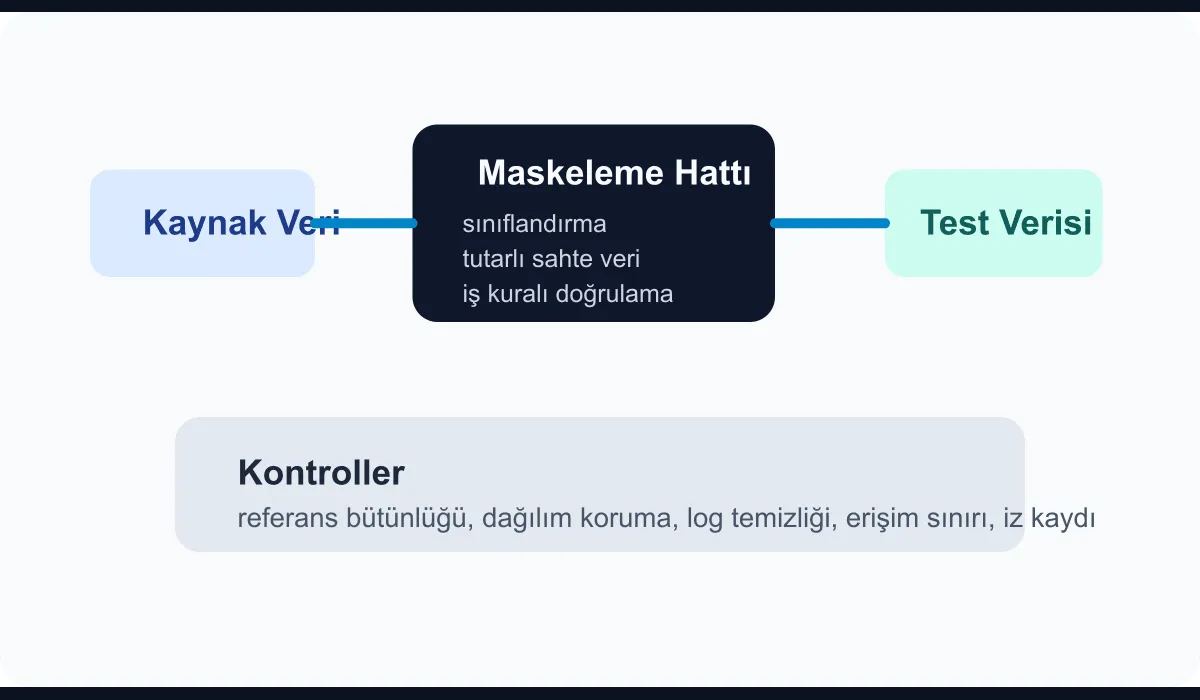
The four stations of a masking factory
In practice a solid model consists of these four stations:
- Source selection: Which tables, fields, and relationship sets are actually needed?
- Classification: Distinguishing personal data, financial data, operational references, and technical metadata
- Transformation: Tokenization, consistent synthetic data generation, range preservation, date shifting
- Validation: Business rules, referential integrity, reporting consistency, and access boundaries
The value of this model is that it prevents starting from scratch every time a new environment is needed.
Why is consistent synthetic data critical?
In ERP systems, the same customer, employee, or supplier appears in dozens of tables in different roles. If you turn “Company A” into “X Ltd.” in one place but rewrite the same record to a different value elsewhere, the test environment looks technically populated but the workflow breaks. That is why consistent synthetic data generation is essential.
The following principles work for consistency:
- The same source identifier must map to the same alias everywhere
- Distributions like segment, country, or currency should be preserved
- Date fields should be shifted as a process flow, not one by one
- Financial magnitudes should be transformed to keep relative, not absolute, relationships
This way integration and reporting teams can work on behavior close to real life.
The security boundary is not built only at the data field level
For the masking factory to be safe, the pipeline itself must also be bounded. A common organizational mistake is masking the data well but leaving temporary work areas and logs unconstrained.
Architecturally, the following constraints matter:
- Access to the raw production copy should only go through an automation account
- Temporary work areas should be short-lived and encrypted
- Transformation logs should not contain sensitive field values
- The output dataset should be transferred only to the target test network
- Each run must leave an audit trail
This way the masking pipeline stops being a new data leak surface.
Why must compliance and engineering sit at the same table?
In ERP projects, security and compliance teams typically approach with a “data must not get out” lens, while engineering teams come at it from a “scenarios must work” angle. When the two groups operate in isolation, either the test data becomes meaningless or the risk appetite climbs. The best result comes from preparing the data classification dictionary jointly.
The dictionary must clearly state:
- Fields that require full masking
- Fields whose distribution is preserved but identity is changed
- Operational references that should not leave the environment but otherwise remain
- Datasets that will be generated entirely synthetically
Once these decisions are nailed down once, data preparation time shrinks substantially.
How is test data success measured?
Success should not be measured solely by “personal data is no longer visible.” These questions matter more:
- Do critical ERP workflows still work after masking?
- Do integration tests produce referential integrity errors?
- Is the test data refresh time blocking teams?
- Can the same dataset be regenerated when needed?
- For audit purposes, can you trace which data came from which source?
Positive answers to these questions show that the architecture is not just safe but also useful.
Conclusion
Building a test data masking factory in ERP infrastructures is a necessary compromise zone between security and engineering. One-off data obfuscation steps break down quickly in growing enterprise setups. By contrast, an automated, traceable masking pipeline that preserves business rules speeds up project delivery and lowers compliance risk. A solid test environment starts with data that is generated safely.