
As trace data grows, teams get squeezed between two extremes: keeping every span is expensive, but overly aggressive sampling causes blindness during an incident. Head sampling reduces this problem early and cheaply; however, since the decision is made before the request outcome is known, it can miss critical error chains. Tail sampling, on the other hand, is far more meaningful in enterprise systems because it decides only after the full request is visible. The price is more careful queue and memory design.
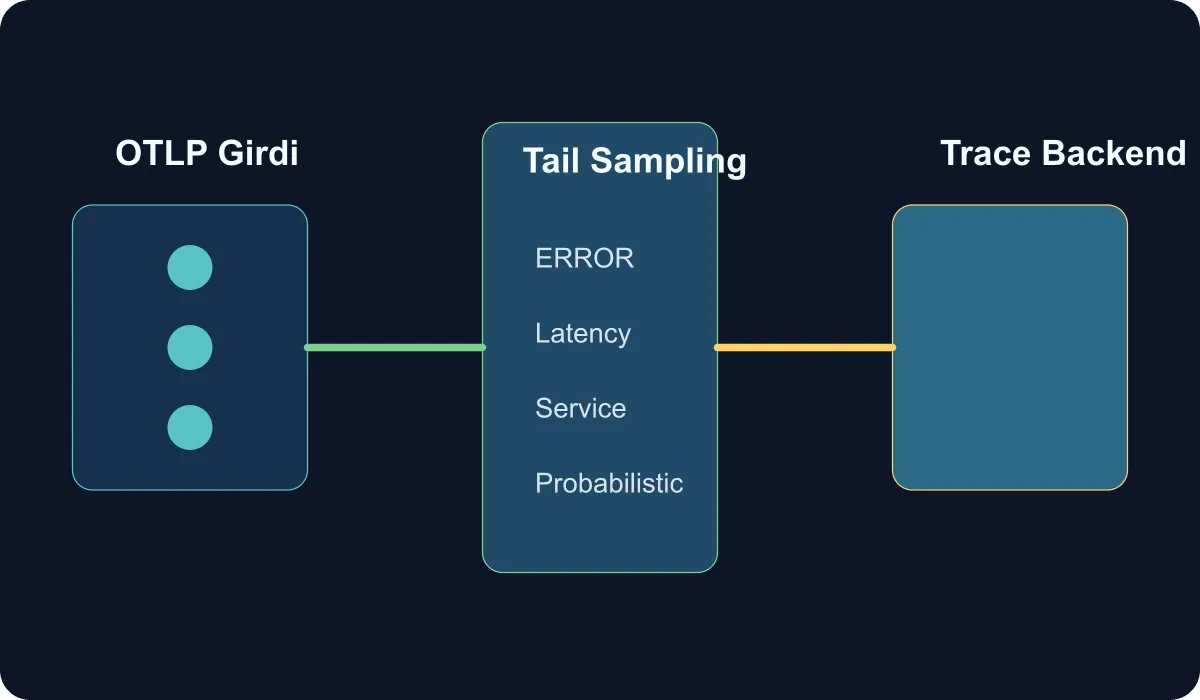
When does tail sampling become necessary?
If you see the following signals, the time has usually come:
- Request volume is high but the meaningful error rate is low
- Health checks and low-value traffic inflate trace storage
- After incidents, the sentence “we don’t have the trace for that request” is heard often
- Cost-cutting pressure starts threatening instrumentation quality
In this situation, the goal is not to chop all data, but to set up a selective pipeline that preserves high diagnostic value.
What is the core design principle?
I recommend three layers for tail sampling:
- Prioritize traces that contain errors or high latency
- Keep a minimum sampling baseline for critical services
- Sample successful and low-impact traffic at a low rate
This model can be read not only by technical cost but also by operational priority. What matters is building the sampling rule based on which questions you want to answer, not based on backend pricing.
Sample Collector pipeline
The example below provides a clean framework for kicking off tail sampling together with memory safety and basic classification:
receivers:
otlp:
protocols:
grpc:
http:
processors:
memory_limiter:
check_interval: 1s
limit_mib: 512
spike_limit_mib: 128
batch:
timeout: 5s
send_batch_size: 1024
tail_sampling:
decision_wait: 15s
num_traces: 50000
expected_new_traces_per_sec: 1500
policies:
- name: keep-errors
type: status_code
status_code:
status_codes: [ERROR]
- name: keep-slow-checkout
type: latency
latency:
threshold_ms: 1500
- name: keep-critical-services
type: string_attribute
string_attribute:
key: service.name
values: [erp-api, payment-gateway, identity-broker]
- name: sample-background
type: probabilistic
probabilistic:
sampling_percentage: 8
exporters:
otlphttp:
endpoint: https://traces.internal/v1/traces
service:
pipelines:
traces:
receivers: [otlp]
processors: [memory_limiter, tail_sampling, batch]
exporters: [otlphttp]In this example, decision_wait and num_traces are critical parameters. A value too low under-collects late-finishing traces; a value too high swells collector memory unnecessarily.
Why does policy order matter?
Tail sampling is not just a “what percentage should remain” problem. It is healthier to think of policy logic in this order:
- First, the classes that must definitely be kept
- Then, requests that are business-critical but technically successful
- Finally, background and low-value traffic
This way, the low-rate general sampling does not overshadow critical error traces.
Which metrics should the operations side watch?
At a minimum, you should wire the following onto a dashboard:
- Collector memory consumption
- Trace acceptance rate after sampling
- Number of traces kept per policy
- Decision wait time and amount of dropped traces
Without these metrics, tail sampling tends to run blindly in many teams as “we think cost dropped.” Yet a misconfigured pipeline produces silent data loss.
What is the common mistake?
Managing all services with a single policy set in one collector pool. ERP, identity, and batch workflows do not carry the same diagnostic value. Ideally, separate policy clusters or even separate collector pools should be considered, at least by service class.
Conclusion
Tail sampling design in the OpenTelemetry Collector is not a trick to reduce trace volume; it is the work of encoding observability priorities. When error, latency, and critical service traffic are preserved while low-value flows are reduced in a controlled way, both cost and diagnostic quality improve together. To get a strong outcome, before the sampling rate, the decision wait time, memory limit, and policy visibility must be set up correctly.