
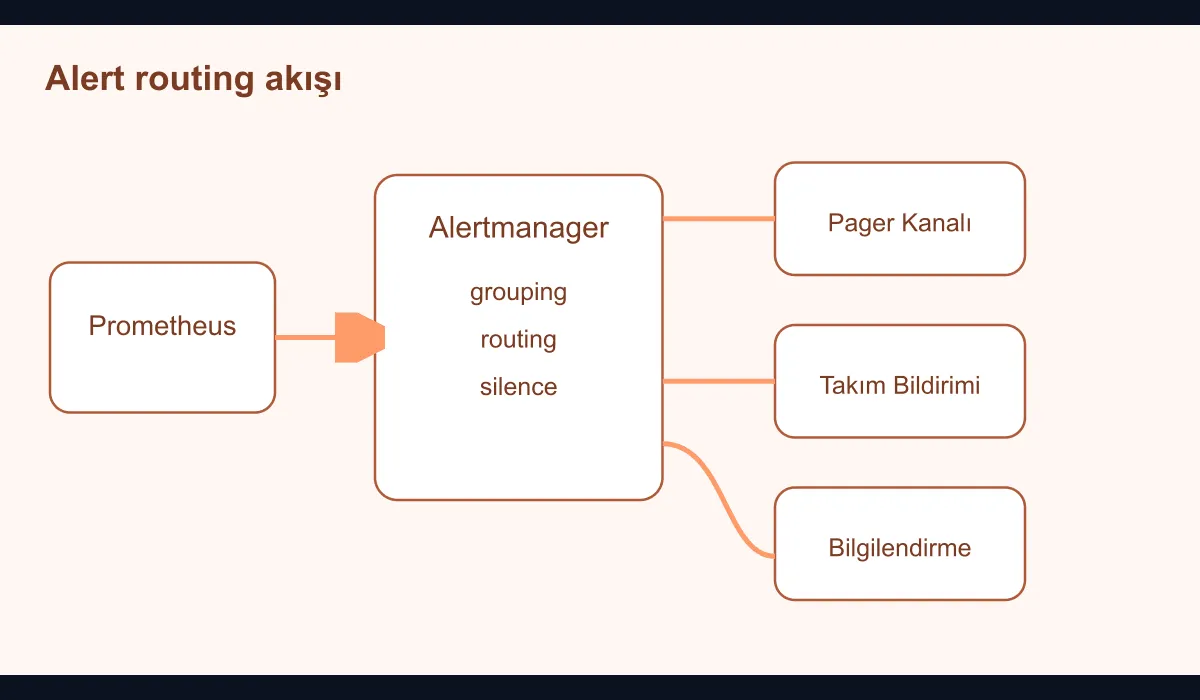
Setting up a monitoring system is relatively easy; alerting the right person at the right time is harder. In many teams, the actual problem is not a lack of alerts but alerts that bounce around the wrong team, with the wrong priority, on the wrong channel. When Prometheus and Alertmanager are used together, it becomes possible to turn that noise into a more manageable route.
Why should routing design be treated separately?
Because producing alarms and operating them are not the same thing. A healthy routing model:
- Merges repeated notifications stemming from the same incident.
- Picks the right recipient based on team ownership.
- Uses different channels and escalation paths according to business criticality.
- Supports silencing and maintenance windows.
When these decisions are undefined, every new rule eventually feeds alert fatigue.
Without label discipline, routing stays weak
Alertmanager routing essentially works on labels. So when authoring alert rules, the following fields must be defined with discipline:
severityteamserviceenvironmentrunbook
If these fields are missing or used inconsistently across teams, the routing tree quickly becomes tangled.
route:
receiver: default
group_by: ['alertname', 'service', 'environment']
routes:
- matchers:
- severity="critical"
receiver: ops-pagerWhich routing layers actually pay off?
In practice, this split provides the most clarity:
- Informational alerts: chat channel
- High priority that requires intervention: pager or phone tree
- Security and access events: a separate security channel
- Non-production environments: a suppressed or low-priority channel
With this model, noise from a test environment does not behave the same way as a production crisis.
Conclusion
A solid Prometheus alert routing design defines the real operational value of your alerting system. With a sound label model, group logic, and ownership-based routing, fewer but more meaningful alerts become possible. Quality in observability is determined not only by what you measure, but also by who you notify and how.