
One of the quietest yet most expensive risks in enterprise infrastructures is the management of machine identities through static secrets that go unchanged for years. CI agents, backup scripts, integration services, and configuration automations often live tied to access keys forgotten somewhere. This setup does not just create a security issue; it also produces serious uncertainty around secret rotation, auditing, and service ownership.
Why should machine identity be handled separately?
For human users, MFA, SSO, and session policies are widely discussed; yet for machines, the same discipline is missing in most organizations. And yet machines:
- Request access far more frequently.
- Often run with elevated privileges.
- Can consume tokens, certificates, or short-lived secrets instead of passwords.
- Need explicit ownership information in audit records.
For these reasons, reducing machine identity management to a “secret storage” problem falls short. The real question is how the identity is born, how it is verified, and how it is revoked.
What role does Vault play here?
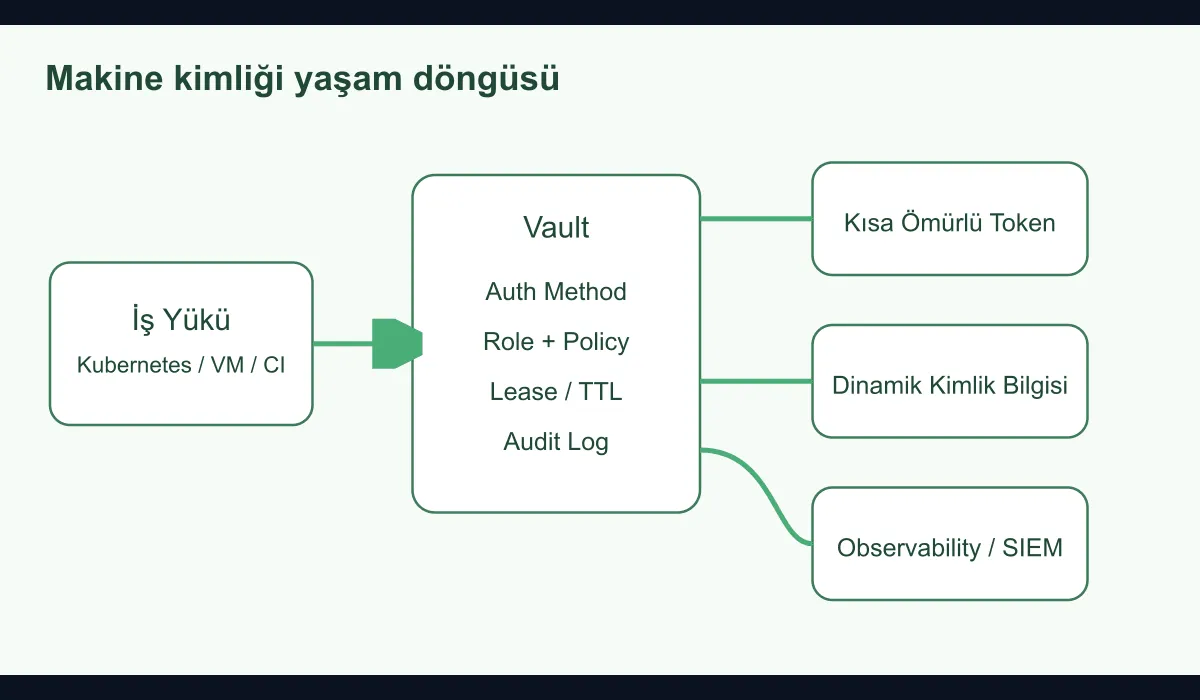
Beyond being a secret storage product, Vault can act as a trusted intermediary layer for machine identities. In a robust model, the process works like this:
- The machine or workload authenticates itself via a trusted method.
- Vault issues a short-lived token according to the matching role and policies.
- The requester is temporarily granted the necessary secret or certificate.
- When the access window expires, the identity becomes invalid naturally.
This approach significantly reduces the volume of stored static keys.
Which authentication methods are appropriate?
Different paths can be chosen depending on the infrastructure:
- Kubernetes service-account-based auth
- Cloud instance metadata-based auth
- AppRole-style controlled bootstrap models
- Certificate-based machine authentication via mTLS
When choosing, the main criterion should not be ease of automation but whether the identity can genuinely be proven at runtime.
How should the policy model be designed?
Access models for machine identities are usually defined too broadly. Instead, apply these principles:
- Define a separate role for each service or automation.
- Separate policies by environment.
- Expose secrets only to paths that genuinely need them.
- Use short TTLs and renewal limits.
- Forward audit logs to your central observability system.
With this model, it becomes clearer which service accesses what, and incident investigations become faster.
Where do operations see the biggest benefit?
Vault-based machine identity management makes the biggest difference in areas like:
- Generating temporary access during server bootstrap
- Short-lived deployment identities in CI/CD pipelines
- Dynamic credentials for databases or message queues
- Auditable management of privileged automation users
In these use cases, eliminating static secrets reduces both leak impact and operational maintenance overhead.
Common mistakes
- Treating Vault as just a password vault
- Handing out long-lived root-like tokens to automation
- Leaving audit logging disabled or scattered
- Combining production and test policies in the same role
- Allowing unlimited token renewals
These mistakes give the impression that you have built an intermediary platform, while in reality you have only relocated the secrets.
Conclusion
Machine identity management is one of the foundational security topics of modern infrastructure. A model built well with Vault reduces static secrets, shortens access windows, and strengthens audit trails. Especially in enterprise organizations with automation, ERP integrations, and multiple environments, applying a serious identity lifecycle to machines is no longer optional but a basic architectural requirement.