
In most organizations, Sev2 incidents look misleadingly “medium severity.” In reality, customer impact is real, business units start applying pressure, teams quickly look around for a decision center, and the tech lead’s desk is hit simultaneously with diagnosis, communication, and change-approval traffic. At that point, the lead taking every decision personally produces short-term reassurance — but within a few hours both pace and team initiative freeze. The right approach is not to scatter decisions randomly; it is to define, before the incident grows, which decision belongs to whom.
Why is Sev2 specifically harder?
Because the command model isn’t as crisp as Sev1, but you can’t shrug it off the way you can with Sev3. Teams land in a dilemma:
- You need to move fast before the impact spreads.
- Yet every change can also turn into a bigger customer impact.
So the tech lead gets pulled into every conversation. Which rollback is safe, which team to call in for support, what to write in external communications, when to send the next status update — it all funnels into one person. After a while, that does not strengthen leadership; it makes the system fragile.
Which decisions does delegation start with?
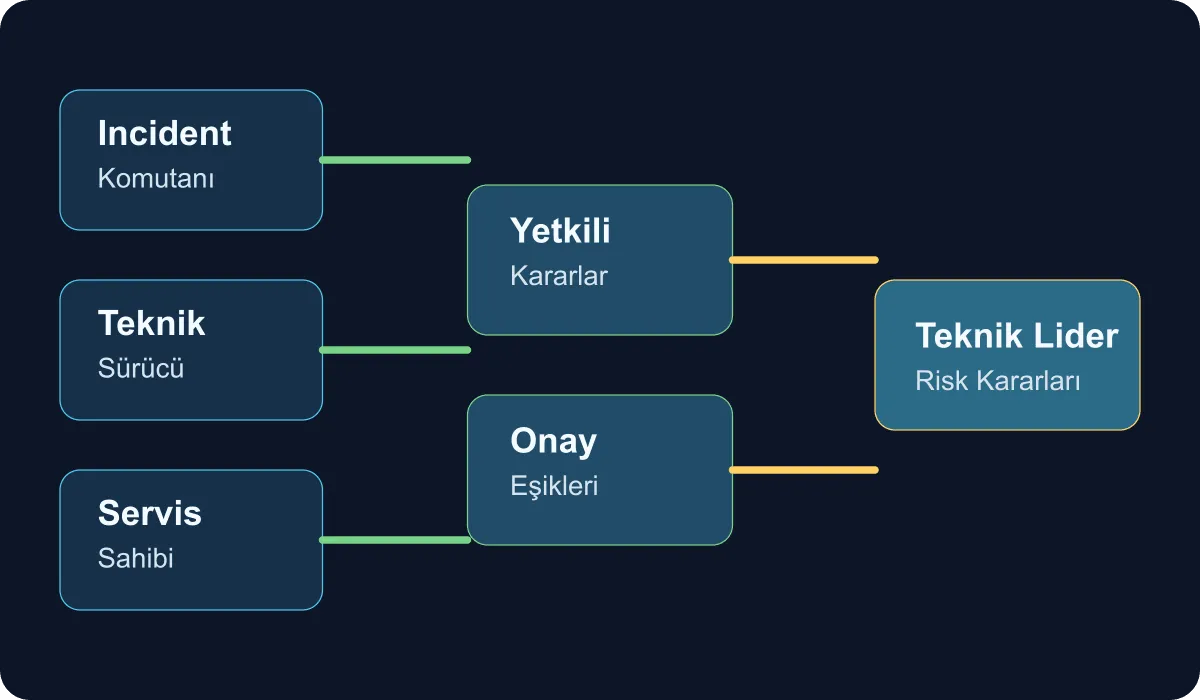
In Sev2 incidents, I find it useful to split decisions into four categories:
- Diagnosis decisions: which hypothesis do we test first?
- Mitigation decisions: rollbacks, feature kill switches, traffic redirection, and similar technical moves.
- Communication decisions: updates to internal stakeholders, support, and management.
- Risk decisions: opening additional changes, going outside the maintenance window, granting a temporary exception.
Without this split, everyone thinks they are talking about technical decisions — when in fact the table is also handling communication and risk decisions.
Who should make which decision?
In a workable model, the roles can be sharpened like this:
- Incident commander: owns pace, time-boxes, and communication rhythm.
- Technical driver: evaluates diagnosis options and rollback candidates.
- Service owner: confirms application behavior, data impact, and dependency risk.
- Tech lead: sets the final threshold for high-impact risk decisions and clears bottlenecks.
The critical point here is that the tech lead is not first-touch on every decision; the lead knows at which threshold to step in. For example, predefined rollbacks, capacity scaling, or feature flag toggles can sit with the technical driver. But rolling back a schema change with data-consistency risk should stay tied to tech lead approval.
Which thresholds need lead approval?
I recommend writing three thresholds explicitly:
- Hard-to-reverse data changes
- Traffic redirections that touch more than one critical service
- Temporary exceptions that introduce regulatory, security, or customer-commitment risk
Decisions outside these should be made as close to the incident table as possible. When the lead is the constant approval node, a damaging reflex forms in the team: responsibility flows up, and the thinking muscle below atrophies.
Why communication delegation needs separate thought
Many tech leads design technical delegation but keep communication on themselves. In Sev2, however, communication delay can be more expensive than a bad technical call. When business units or support teams cannot get information, they generate their own narrative. So this responsibility deserves its own owner:
- Sending a status summary every 20 or 30 minutes
- Updating the known impact in a single sentence
- Separating estimate from evidence
- Writing the next check-in time
That flow can sit with the incident commander or with an operations communications owner. The tech lead only reviews the risky portion of the message.
How do you teach a delegation culture?
In senior engineering practice, delegation is not abandoning work — it is building a teachable decision model. I think three post-incident questions are powerful here:
- Which decision did we slow down on by holding it at the center?
- Which decision did we speed up by pushing it to the front line?
- Which threshold remained vague and caused unnecessary escalation?
Used regularly, these questions mature the team not just on technical resolution but on decision distribution.
What is the most common mistake?
Treating delegation as a luxury for calm periods. The real need shows up exactly during pressure. If teams are not rehearsing rollbacks, feature toggles, capacity scaling, and temporary routing decisions on normal days, then in a Sev2 everyone instinctively turns to the most senior person. The tech lead burns out, the team goes passive, and the incident drags on.
Conclusion
For tech leads, decision delegation in Sev2 incidents is not splitting authority — it is preserving response rhythm. With clear role definitions, explicit approval thresholds, and dedicated communication ownership, the tech lead no longer has to chase every detail. Instead, focus shifts to the quality of the genuinely high-impact decisions. Sustainable incident management in enterprise teams draws its strength from precisely this distinction.