
When active-active architecture comes up for enterprise ERP systems, the discussion almost always jumps straight to the core: how the database will replicate, how financial transactions will be ordered, whether the licensing model will support it. In practice, however, the more achievable area is usually the integration layer. Keeping the ERP core as the single write authority while designing the surrounding integration corridor as active-active increases resilience and makes the enterprise transformation more manageable.
Why the integration corridor instead of the core?
Because in most organizations the ERP core is hard to move due to strict consistency, license constraints, and operational habits. The integration layer, by contrast, can behave more flexibly:
- API gateway
- Message queue
- Transformation services
- Event routing layer
- Partner connection adapters
When this corridor runs active-active, a single-region loss produces a lower outage impact for partner traffic and internal system calls. The ERP core, meanwhile, can stay on a controlled failover or single-writer model.
What is the main principle of an active-active corridor?
In structures like these, I see the following principle as critical: replicate delivery, not the transaction. That is, both regions can accept messages at the same time, validate them, and queue them; but the effective write behavior toward the ERP is bounded by specific consistency rules.
Thanks to this distinction:
- Edge systems don’t stay tied to a single region
- Traffic load can spread across both sides
- Queue and transformation layers scale horizontally
- Consistency pressure on the core is held under control
Which risks must be solved up front?
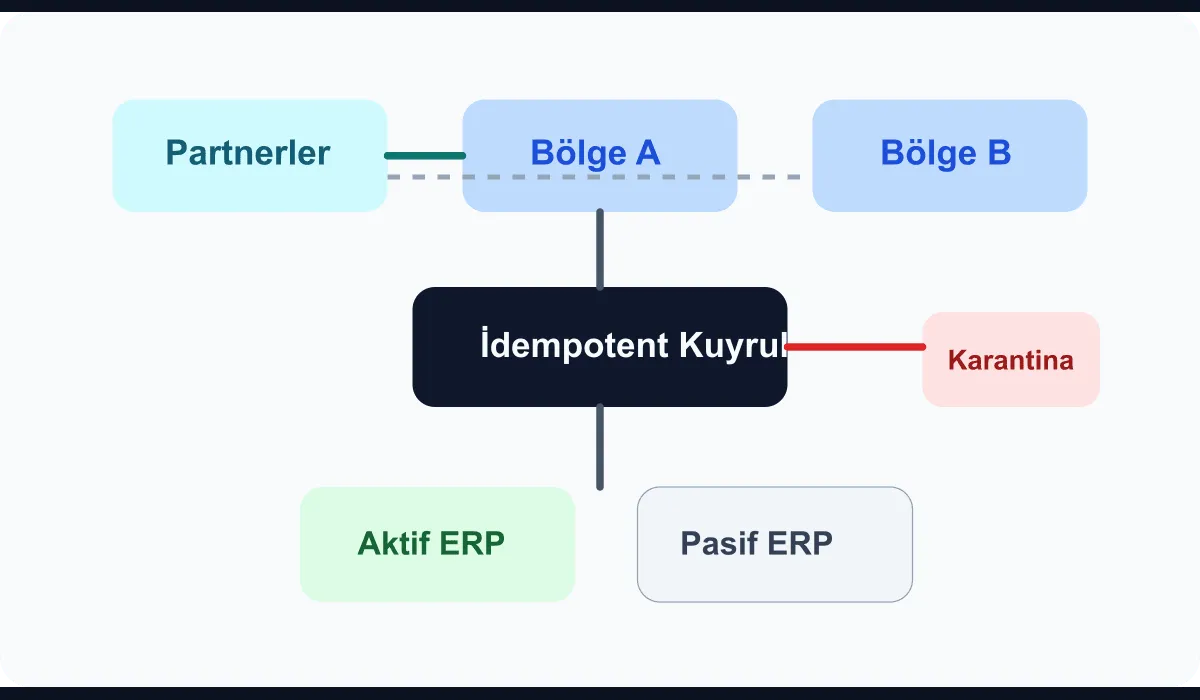
Building an active-active corridor is not just about adding a load balancer. The following topics in particular must sit at the heart of the architecture:
- Idempotent transaction keys
- Region-independent sequence identifiers
- Tolerance for delayed delivery
- Dead-letter and quarantine flow
- Replay limits
If the same order, collection, or stock movement can arrive from two regions at different times, the integration corridor’s job isn’t just transport; it is to absorb duplicates safely.
What should the traffic-routing model look like?
In a good model, north-south traffic is separated from east-west scenarios. Partners and internal services arrive at regional ingress points by the shortest route. At these ingress points:
- Authentication
- Schema validation
- Basic rate limiting
- Correlation ID generation
- Safe handoff to the queue
are performed. In the next step, messages are forwarded either directly to the active ERP region or to the integration orchestration layer that knows the consistency rules.
This structure also creates a clear boundary of responsibility between the network and application teams.
Why is observability so critical?
Because in an active-active corridor, “the system is up” is not a sufficient sentence. The real questions are:
- How much traffic did each region take?
- By what proportion did duplicate deliveries grow?
- Which partner ended up in the quarantine queue?
- In which region did the ERP write slow down?
- After replay, was there any data inconsistency?
So the telemetry model must carry labels for business key, region, adapter type, and delivery outcome. Otherwise, the resilience design cannot be read during operations.
When does this architecture not make sense?
In some organizations integration volume is low, partner count is small, and a single-region outage can be tolerated. In that case, an active-active corridor can be unnecessary complexity. Also, if the ERP core triggers heavy non-idempotent side effects, the transaction contracts must be cleaned up first.
So the active-active corridor is not a fashion but an answer to specific conditions:
- When there are many external systems
- When regional outage risk is serious
- When business continuity pressure is high
- When integration traffic is growing faster than the ERP itself
Conclusion
In ERP infrastructures, the active-active integration corridor is one of the practical ways to gain high availability without straining the core. When designed correctly, it scales the acceptance, queueing, and transformation layers across two regions while preserving the controlled consistency model on the core ERP side. The real craft in enterprise architecture is not forcing the same high-availability pattern onto every layer; it is choosing correctly which layer should multiply by how much.